How AI Works: Part 4: Supervised and Unsupervised Learning Models
How Artificial Intelligence Works
Part 4: Supervised and Unsupervised Learning Models
Introduction
So in the previous post, we finally created our first working neural network, and trained it to learn how to calculate a XOR function. Pretty easy stuff. But for more complex problems, problems that would take humans a very long time to figure out with just their monkey brains alone, we need better learning method than just a genetic algorithm. Now there are many, many learning categories, but they can all fit within three different types: Supervised, Unsupervised, and Reinforcement learning models. These models serve different purposes and are used in different scenarios.

Supervised Learning
Supervised learning is a group of training methods where many correct input output pairs are known, and the AI is trained based on said input output pairs to hopefully be able to learn how to predict future input output pairs.
In other words, it's a bit like if I showed you 100,000 pictures of dogs and cats, and told you which was which. Then I showed you a brand new picture you've never seen before, and told you to classify it as a dog or cat.
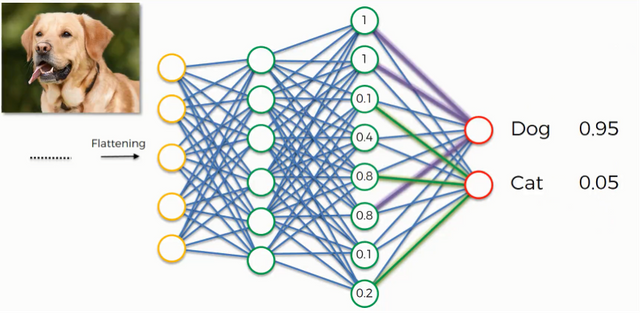
Essentially, when you're trying to solve a problem using supervised learning, you should know some of the correct answers. If you have a large list of input output pairs, for a large list of data points, , pictures of cats and dogs that are labelled, then supervised learning will probably serve you well.
There are a couple algorithms used in supervised learning:
Linear Regression
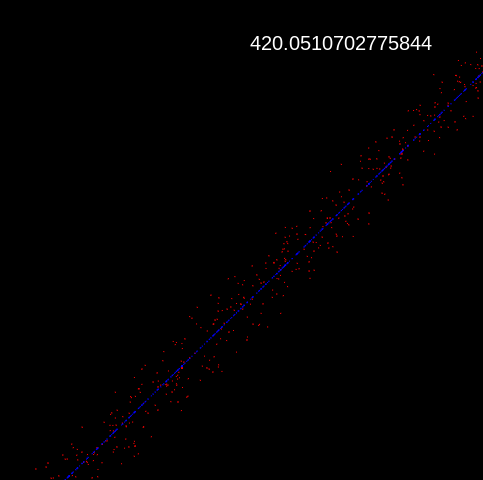
Linear regression is one of the simpler supervised learning algorithms. It's like trying to find the line of best fit in middle school. It's simi to ats, where the average cost is found for each input-output pair that the neural network generated compared to the original. Then, a few variables are changed until the cost (error) is as low as possible. The one I made can be seen doing it's work here, and the source code can be found here. I wrote it mostly as a self project a few weeks ago, so I apologize for the messy code, but really, the concept is really simple.
Logistic Regression
Logistic regression is similar to linear regression, but is used for classification problems. As an example, say you want to predict diabetes in humans. You have a huge dataset showing human weights and a true/false value. Logistic regression is simply a way of finding out the probability of a given input being in one category or another, in this case, finding the probability of a human having diabetes.
You may be asking yourself, why can't we just use linear regression for this? I actually asked myself this while learning about logistic regression. Let's think about this for a moment. Linear regression is all about finding the 'line of best fit' of a dataset. However, when there are only two possible y positions, like 0 and 1, it becomes impossible for a proper prediction to be done. The best scenario that could happen would be a line between the two possible y coordinates, leaning more towards one side or the other.
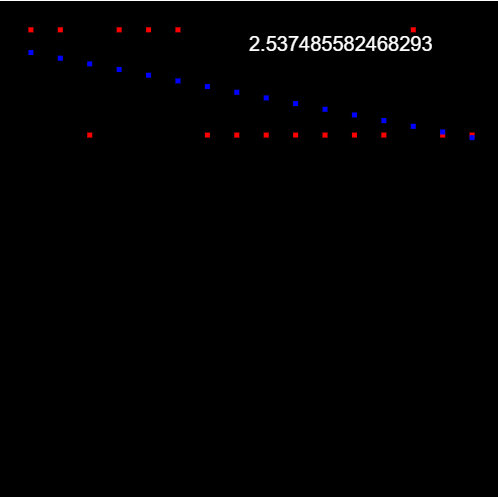
Like this
What could be done? Well, do you remember the Sigmoid function from our talk about neural networks? If you don't, the Sigmoid function is an activation function for a neural network, that takes an input of any size, and outputs a number between 0 and 1. And for the logistic algorithm, it has to take an input of any size and predict an output that's either 0 or 1 (true or false). So all we do is combine them. We write a learning algorithm similar to linear regression, but we plug the output to a Sigmoid function ( or some other activation function ). So then, to calculate the costs it's the same, except you get the Sigmoid of the function. Then, the network will predict the chance of something happening. With the example of diabetes, the network could predict that if you're 250 pounds, you have a 73% chance of having diabetes.
(Quick note, these examples for linear and logistic regression are pretty simple, predicting one output from one input. However, regression can use multiple inputs and multiple outputs, known as multilinear regression).
Decision Trees
(Side note: I've never done much work with decision trees, so I apologize for any errors).
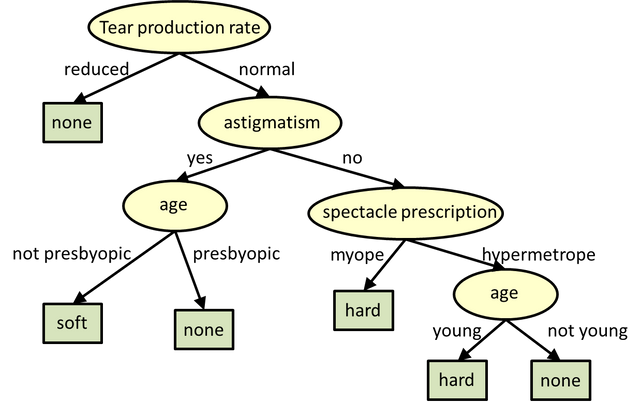
Source
Decision trees are possibly one of the most interesting types of neural networks I've come across when learning. It's essentially looking into the future, and viewing all possibilities before performing an action. Basically, you start from one of several starting conditions, and view all of the possible moves for x amount of moves into the future (like seeing all the possibilities of moving a certain piece in checkers). Then, based on an algorithm that the programmer created, it automatically decides what the best possible move should be, using a cost or reward function, and going down that path, repeating the steps until it finds the most optimal path.
You may realize, if you try to create a decision tree for game (like checkers or tic-tac-toe), that the number of possibilities to calculate can quickly grow. For tic-tac-toe, as an example, the number of possible moves is 9!, or 352,880 moves! To help to counter this, there are many rules that can be implemented into decision tree algorithms to help lower the number of possibilities to calculate. For the sake of time (this post is much more complex than I expected) but further reading can be done here.
Backwards Propagation
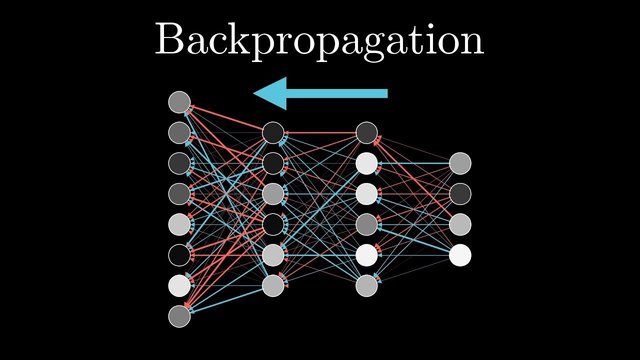
Source
Now, we've finally reached neural networks. In the previous few posts, we've covered, we combined neural networks with a genetic algorithm. However, that is just one of many learning algorithms you can use. One of the most popular ones for neural networks is backpropagation. Without going into too much detail (for today at least), backpropagation (also known as backwards propagation) finds the average error of every weight and bias, and finds the best way to change said weights and biases. We'll be going much deeper into this in a future post, but for now, just know that we start from the end weights, and work our way backwards (hence, backpropagation).
Unsupervised Learning
Unsupervised learning is essentially when a learning algorithm doesn't involve pre-labeled data.
Unsupervised learning is used when you have unlabeled data. It helps to find patterns and structures within data. For example, you have purchases from every person at your store, and you want to figure out that customers who buy x item tend to buy y item, like on Amazon. There are a few Unsupervised Learning Algorithms.
Clustering
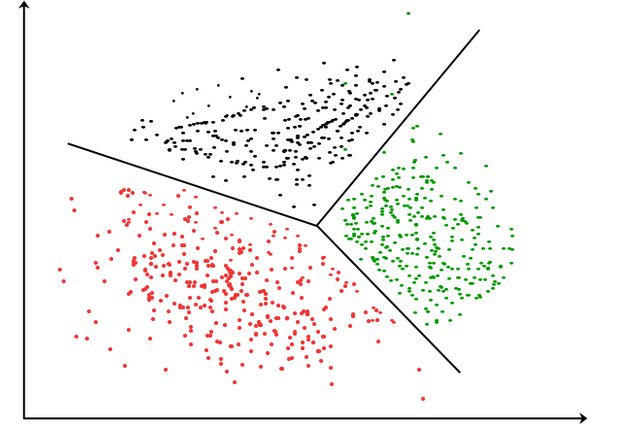
Source
Cluster analysis is taking unlabeled data, and trying to find groups/commonalities/clusters
There are many different models for cluster analysis, but I'll talk about a few:
Centroid Clustering is where you choose random data points to be the 'centers' of your clusters. You then put different data points into different clusters depending on how 'close' they are. You can segment your data into as many clusters you'd like.
Density Clustering is when you create clusters based on how densely populated certain data points. Basically, if there's a huge group of data points in one area, you know that they're probably closely related to each other. This is different from centroid clustering, since in centroid clustering, you randomly define the 'centers' by picking random data points.
Both of the algorithms listed above are hard clustering algorithms, where every data point is in a cluster. In Distribution Clustering though, it's like a version of density clustering. Basically, each point is given a probability of being in each density cluster. For example, points very close to each other would have a high probability of being in the same cluster, while having low probabilities of being in different clusters. This algorithm is used since there is always a chance that our clusters could be wrong, and if we had to default into less probable clusters, it would be easier.
Anomaly Detection
Anomaly detection is what it sounds like, it's finding data points that are very different from other data points, or anomalies. To be honest, I can't wrap my head around anomaly detection right now, though in the future I may cover it more deeply.
Reinforcement Learning
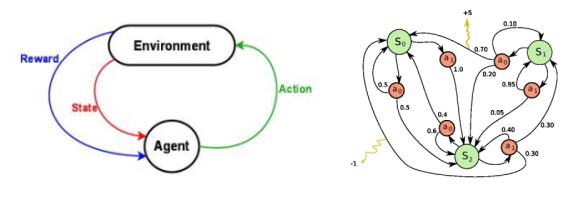
Source
Reinforcement learning is, in my opinion, the most interesting of the 3 categories. Reinforcement learning is more like unsupervised learning, where there isn't any labeled data. However, it differs in that models are given rewards or punishments that help to reinforce the end goal. Basically, the model isn't exactly given clear instructions on how it should do certain tasks. It's just given rewards for doing certain actions, and punishments for doing other actions. Actually, the learning algorithm that we built in the previous post is a reinforcement learning algorithm).
There are 3 aspects to a reinforcement learning algorithm. There's the agent, environment, and possible actions. The agent views the information given to to it, performs an action available to it, and then views how it's environment changes. Then, the agent adapts and continues, based on the rewards and punishments that the programmer built in.
As an example, say you want to develop a machine learning algorithm that can learn how to play pong. The agent, would be the paddle, as that's the 'object' in the game that the AI can change, and it's possible moves would be moving up and down. The environment would be everything, from the players' coordinates (including the opposing player), the ball's direction and velocity, and each players' direction and velocity.
There are many reinforcement learning algorithms:
Genetic Algorithms

Source
Genetic algorithms are based off of natural selection/evolution/survival of the fittest. You start with many random agents who all interact in the environment around them. Then, the algorithms have to compete with one another (just like with living organisms in nature). This can be done in a few ways, like the agents could compete for actual resources in the code, they could be independent of each other but their fitness (how well they each individually did) could be noted, or they could try to outscore each other in a game, etc. No matter what, you need a way to figure out how some of the random algorithms did compared to others.
As an example, our XOR calculating algorithm was in fact a genetic algorithm!
Q-Learning

Source
Q-Learning is another reinforcement algorithm, though it's more heavily based off of a reward/punishment cycle than our semi-random search of genetic algorithms. It actually learns much more closely to how animals learn.
So Q learning is one of the simpler reinforcement learning algorithms. There are 2 main parts two it, the reward matrix and the 'memory' matrix (if you don't know what a matrix is, just think of it as a set of arrays). At first, the memory matrix is empty, meaning the AI knows nothing. The AI then randomly interacts with the environment through it's possible actions until it stumbles into a reward or action. Then, as the AI explores it's environments and possible actions, it's memory is updated and changes over time, and depending on how the programmer set a setting of the AI, it will rely on it's memory more or less. It learns how to get rewards more quickly, or learns to take it's time in order to maximize it's possible rewards. I personally think that this style of machine learning is really interesting, and may do a deep dive on it in a future post.
State-Action-Reward-State-Action (SARSA)
State Action Reward State Action or SARSA is very similar to Q-Learning, so going into detail isn't very necessary. The only difference is that with SARSA, it figures out how to interact optimally with it's environment by viewing it's current situation, whereas with Q Learning, it figures out how to interact with it's environment with possible future actions.
For now, that'll be our introduction to the difference between various supervised and unsupervised learning algorithms. While there are many, many many more that we could talk about, and we hopefully will eventually, this post is already far behind schedule, and involved way more research then I initially thought it would. In all though, I hope to be posting many more posts about artificial intelligence (relatively soon).
Sources:
Supervised Learning - Wikipedia
Backpropagation - 3Blue1Brown
Gradient Descent - 3Blue1Brown
Supervised vs Unsupervised Learning - Towards Data Science
Linear Regression - Wikipedia
Logistic Regression - Medium
Multilinear Regression - TowardsDataScience
Decision Trees - Wikipedia
Decision Trees - TowardsDataScience
Decision Trees - GreyAtom
Decision Tree Pruning - Wikipedia
Unsupervised Learning - Wikipedia
Backpropagation - Wikipedia
Gradient Descent - Wikipedia
Backpropagation - Brilliant
Neural Networks and Backpropagation - Assad MOAWAD
Cluster Analysis - Wikipedia
Types of Cluster Analysis - Decisive Data
Clustering - GeeksForGeeks
Anomaly Detection - TowardsDataScience
Reinforcement Learning - Wikipedia
Reinforcement Learning - GeeksForGeeks
Reinforcement Learning Algorithms - Towards Data Science
Q-Learning - Wikipedia
Q-Learning - Mnemosyne Studio
Q-Learning FloydHub
SARSA
Congratulations @bootlegbilly! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Hello,
Your post has been manually curated by a @stem.curate curator.
We are dedicated to supporting great content, like yours on the STEMGeeks tribe.
Please join us on discord.